計算機の季節がやってきました。大石です。
計算機を購入する際に、最近ではAMDというオプションも出てきて、IntelとAMDどちらにするのか迷うところも多いと思います。この記事では、両CPUでNICAMやSPEEDY-LETKFを回してみます。
環境
- Intel
- CPU: Intel xeon gold 6238 (22C44T) 2 socket
- Memory: 2400MHz 32GB x 4ch x 2socket
- AMD
- CPU: AMD EPYC ROME 7342 (24C48T) 2socket
- Memory: 3200MHz 8GB x 8ch x 2socket
というような感じです。NICAMというのは、気象モデルのうちの1つで、スケーラブルに動作することが特徴です。
今回は114㎞解像度で1メンバー6時間予報を行う時間を計測しました。
IntelのCPUでは、AVX512命令を有効にして、EPYCのほうでは、サポートしているAVX-2の命令までで実験しています。
コンパイラはIntel fortran compiler v19.1.0.166 を使っています。最適化は基本的に-O3を付けていて、SIMD命令の種類を変えたりunroll0の有無で最適化を変えて計測しました。
MPIにはMPICHを使っています。
NICAM16.3の結果
| Tsubasa (AMD) | Nozomi (intel) | |
|---|---|---|
| AVX2 & unroll0 | 47 [s] | 107[s] |
| AVX512 & unroll0 | × | 97 [s] |
| AVX512 only | × | 107 [s] |
この結果は、メモリの帯域が広いほど結果が良い、またキャッシュの構造が結果に影響を与えていることを示しています。AMDでは、128MBのL3キャッシュがあり、Intelではその容量は30MB程度なので、その差がキャッシュヒット率に影響を与えているものと思われます。また、メモリの帯域が3倍近く高いことも結果が出る理由だと考えられます。
SPEEDY-LETKFの結果
SPEEDY-LETKFでは、LETKFのパフォーマンスを主に測ることができます。MPIにはNICAMの時とは違うOpenMPIと、NICAMの時と同じintelのコンパイラを使いました。
44メンバーで、44並列です。
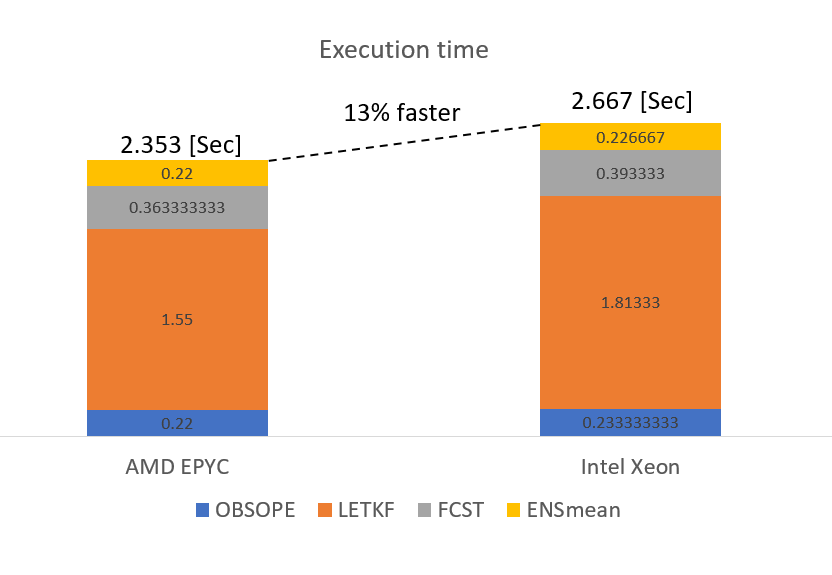
こんな感じの時間分布になっています。LETKFは本来メモリ帯域はそこまで重要ではありませんが、それでもやはりEPYCのほうが速いようです。
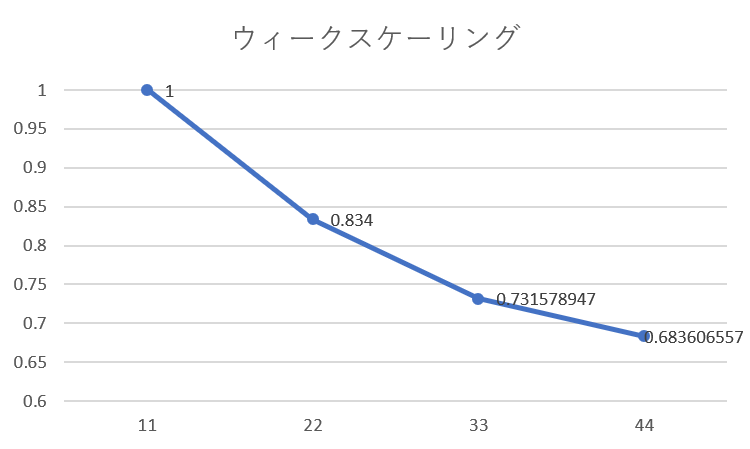
ちなみにスケーラビリティはそこまでよくなさそうです。11プロセス並列を1~4つ同時に動かすと、性能は0.68まで下がっています。おそらくコア数が上がるとさらに悪化すると思われます。48コアあたりが無難でしょうか?
まとめ
アプリケーションがメモリ帯域バウンドの場合はIntelのAVX512ってそんなに速くならないんですね。これからはAMD製品を中心にクラスタを構成しようかと考えてみたいと思います。
気象関係の方、データ同化の研究をする方はIntelだけではなくAMDも悪くない選択肢かもしれません。ただ、コア数は多ければいいというものでもなさそう。試しに少ノードだけ買ってテストしてみていい感じのスイートスポットを探してみてください。