
インフラを整備している大石と土屋です。研究室の物理サーバと整備についてを紹介します。
小槻研究室では計算資源を有効に使うためにインフラを整備する専門のチームがあります。この記事では計算インフラがどのように整備されているのか説明します。
この記事の想定対象者としては、
- 研究室などでサーバ管理をしている人
- 小槻研究室で計算機整備をしてみたい人
- 小槻研究室の計算機資源が気になっている人
としています。
最初にサーバハードウェアを紹介し、その後にソフトウェアスタックを紹介します。
サーバハードウェアの紹介
小槻研究室では大きく3種のサーバを持っています。CPU演算サーバ、GPUサーバ、ストレージサーバです。それらを高速なネットワークでつないだりして運用しています。
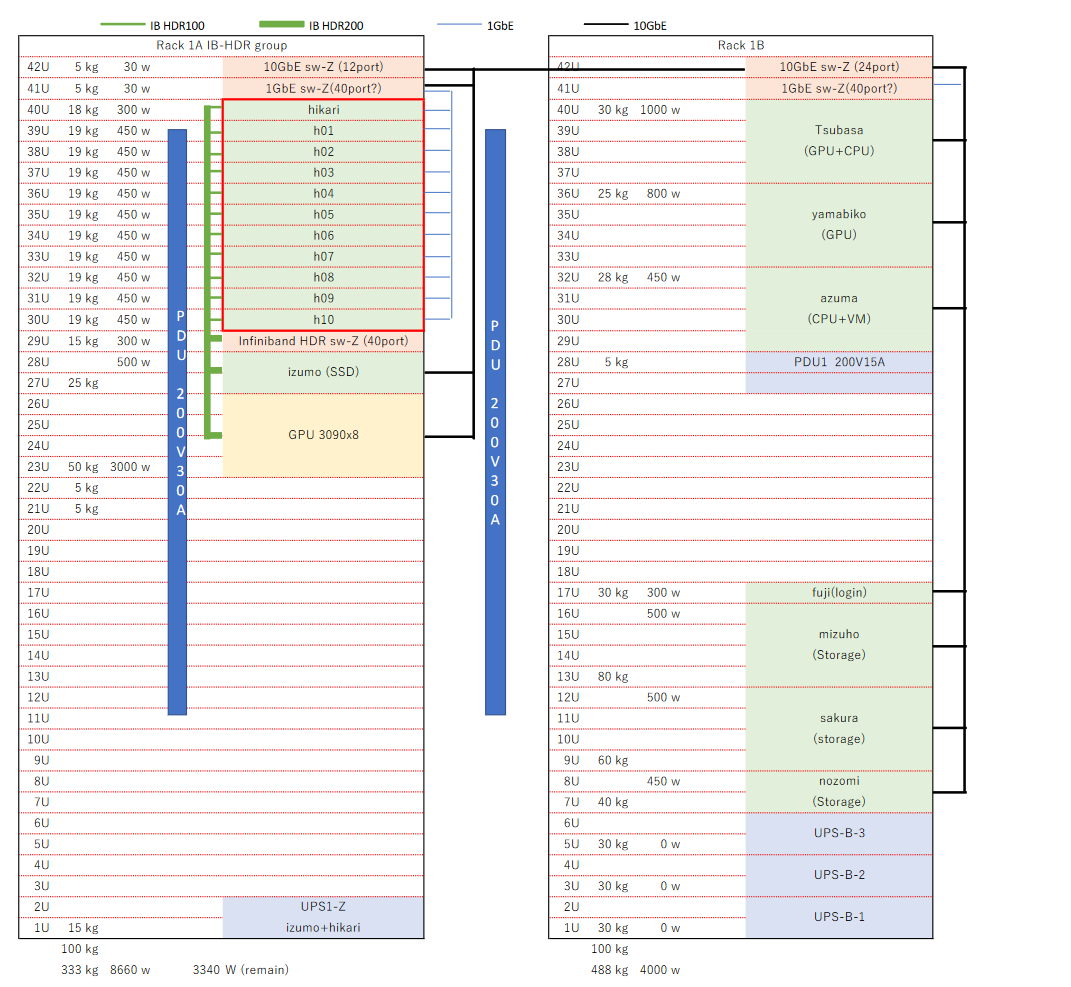
限りあるラックのスペースと今後の拡張性、電源の余裕を見ながら全体の配置構成を決定します。
この場合はInfinibandを使っているラックとそうでないラックを分離し、Infinibandの配線コストを最小にするように工夫しています。
hikari(CPUクラスタ)
CPUの計算を行うための専門のCPUクラスタです。CPUを使って計算をする気象モデルを高速に計算させることができます。全球の気象予報の6か月データ同化を3日以内で完了させられる見込みです。

GPUサーバ起動の様子
GPUサーバです。GPUは機械学習や画像処理、グラフィック処理を高速に行うことができます。

GPUの例:RTX 2080ti

上からtsubasa(CPU&GPU), yamabiko(GPU), azuma(VM)サーバ
その他のサーバです。tsubasaはGPU演算、CPU演算やVM(バーチャルマシーン、仮想マシン)、yamabikoはGPUタスク向け、azumaは細かく分割して研究生のVM(小さなタスクなど)で使われています。

izumo(SSDサーバ)
高速なファイルIOを支援するためにSSDのファイルサーバ(>70TB)があります。ファイルIOがボトルネックになるアプリケーションでも高速に計算を行うことができます。一部ノードにはInfinibandによる高速な通信でファイルIOを行うことができます。実測で12GB/s以上の性能を出すことができます。InfinibandとEthernetのルーティングも行う予定。

裏配線の様子。ごちゃごちゃですが、今後引っ越しにより改善するはず...
Infinibandによる通信は、200GbpsのHDR200と100GbpsまでのHDR100に分かれます。小槻研究室のサーバは、100Gbpsまでで十分なサーバには100GbpsのHDR100のNICとスプリットケーブルを使用してコストを下げています。一方で200Gbpsの通信を行う場合はHDR200の規格で通信を行います。izumoのSSDサーバではHDR100では性能が飽和してしまう可能性があるため、HDR200のフルスペックで通信しています。

10GbEスイッチ
その他のサーバについても1GbEでは帯域が不足することが多いので、10GbEを搭載したサーバを基本としています。私たちの研究室では基本的に最低限10GbEを使って通信ができるように整備しています。
10GbEのスイッチについては、microtikの12Portのスイッチが相性問題が発生せず調子が良いです。ところで24PortのNetgearの10GbEとDellのNICは相性が悪いみたいで現在は1GbEで使用しています。(Infinibandがあるためそこまで問題にはなってません)

上からfuji(ログインノード)とmizuho(HDDのNAS)
上からログインノード、mizuhoのHDDのNASです。HDDのNASは積載密度の高い45ドライブが入るタイプの4Uサーバです。HDDの交換には、ラックを固定したまま内側の引き出しを引き出して交換します。液晶に故障したHDDの情報が出るため、容易に交換が可能です。

sakura(HDD)とnozomi(HDD, CPU)
sakuraは現在ストレージとして使っています。mizuhoでは完全にsoftwareベースのRAIDを使っていますが、sakuraではmegaraidのRAID6を使っています。RAIDカードを使うとライトホール問題が発生する可能性があるため、UPSなどを使って予期せぬ停電を防ぐ必要があります。ソフトウェアベースのNASでは、これらの欠点を克服している点があり、sakuraより安心して運用できます。また、U.2によるSSDによりライトキャッシュを追加することなどが可能であり、mizuhoに少しずつ機能を移行させていく予定です。
ソフトウェアスタック
ソフトウェアから見てみます。サーバを効率よく利用するための資源を提供しています。サーバのユーザ管理、環境を仮想化するためのコンテナ仮想化、ジョブを効率よくスケジューリングするためのジョブスケジューリングがあり、管理者はその他にもAnsibleによる自動構成や、障害対応などを目的としてサーバの監視システムも行います。
ユーザ管理
ユーザ管理はFreeIPAを用いています。FreeIPAはアカウントの統合管理に使用しています。FreeIPA上で
- アカウントを作成
- ユーザのアクセス権限を制限
- autofsの設定
- sudoの権限を設定
したりできます。
コンテナ仮想化
コンテナ技術としてはSingularityを利用しています。Singularityはユーザ権限でコンテナを実行できる技術で、rootlessのDockerとは違いuidなどを考えずに使用することもできます。GPUを使うこともできます。また、自動的にhomeをマウントしたりデータセットを統合的に扱うことができます。
- ユーザが独自にコンテナを開発し、独自の実行環境を提供できる点
- 管理者が環境を作ることで生じる環境の競合が生じない点に優れている
- Pythonのライブラリのバージョン、CUDAなどのライブラリの競合が起きない
- ノードによらず、様々な環境で実行できる点(ABCIなどでも実行可能)
ジョブスケジューリング
CPUやGPUのスケジューリングはslurmを用いています。
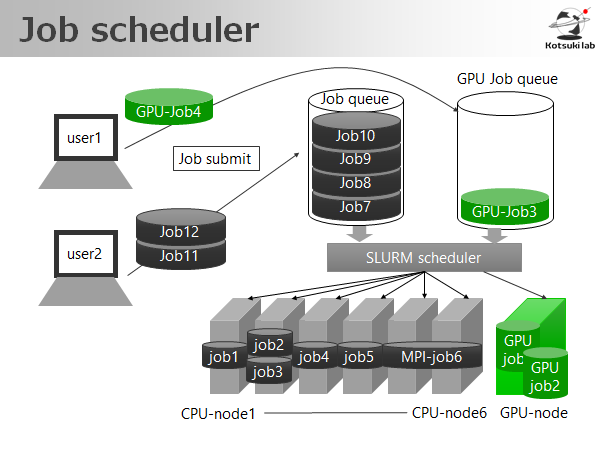
ジョブスケジューラの概要図
ジョブスケジューラはCPUやGPUのタスクを効率よく割り振るための機構で、ユーザから投げられたCPUのジョブやGPUのジョブをそれぞれのノードに分配します。分配するときにはそのジョブの実行時間などを考慮して基本的にFIFOでスケジューリングされます。(将来的にはもっと高度なスケジューリングができるようにしたいですね)
ジョブスケジューリングの長所は、いくつかあります。
- ユーザに対してノードの割り振りを管理者が行う必要がない点
- ユーザが必要最低限のリソースを簡単に利用できる点
- 1ユーザで簡単に複数のジョブを発行できる点
- 複数のユーザでリソースの競合が発生しない点
- 管理者がノードのメンテナンスが必要な場合にノードを引き出すことができる点, 新規ジョブを割り当てしない (drain function)
このような長所から今後はなるべくスケジューラ越しにタスクを実行するようにしたいと思います。
監視システム
監視システムというと、常にみられている怖い印象もありますが、ここではノードの状態を監視し、問題が発生していないかやトラブルシューティングの目的で監視が行われます。
grafana, prometheusによる監視を行っています(藤村さんが整備中)。
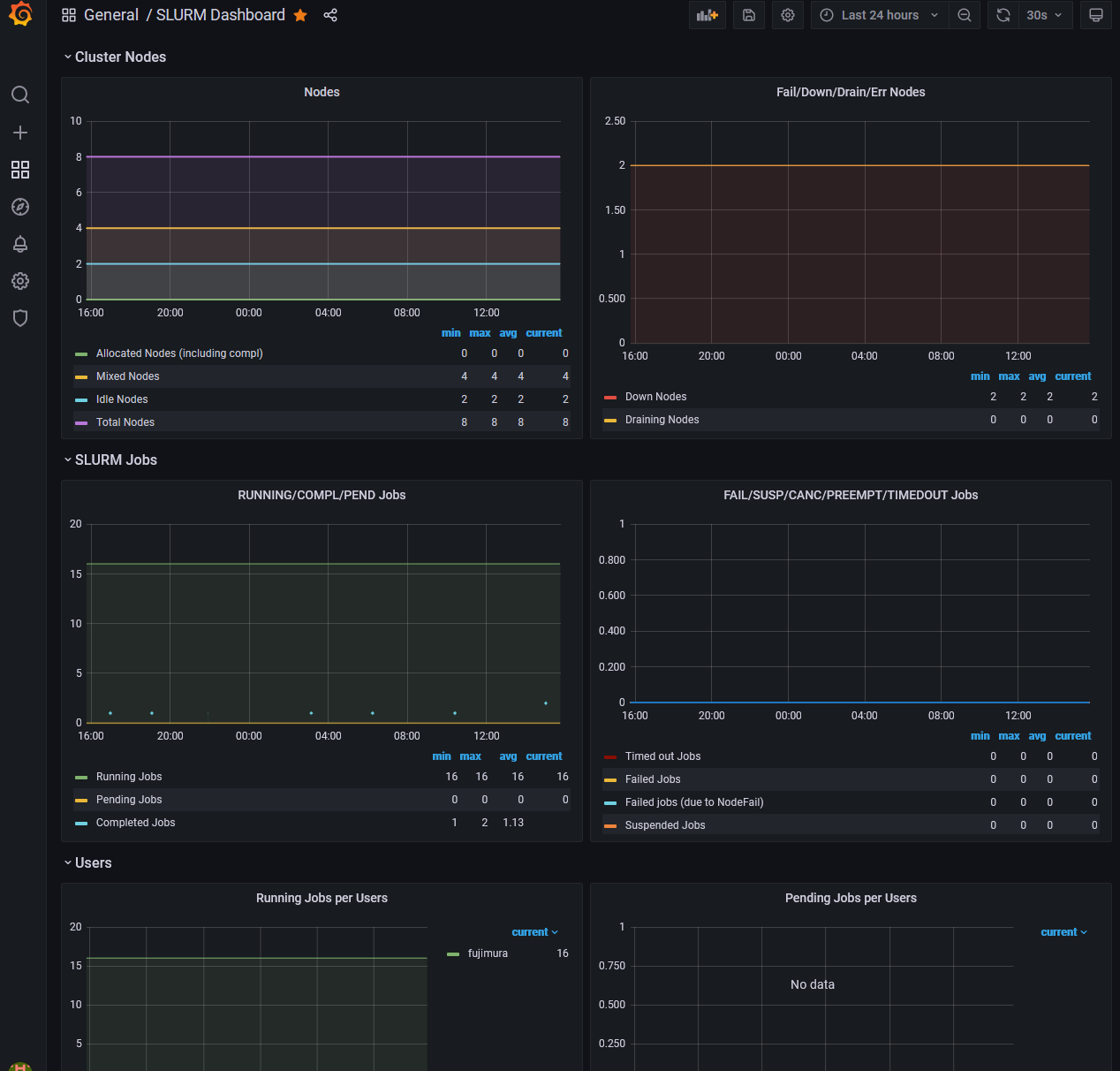
ジョブスケジューラの監視
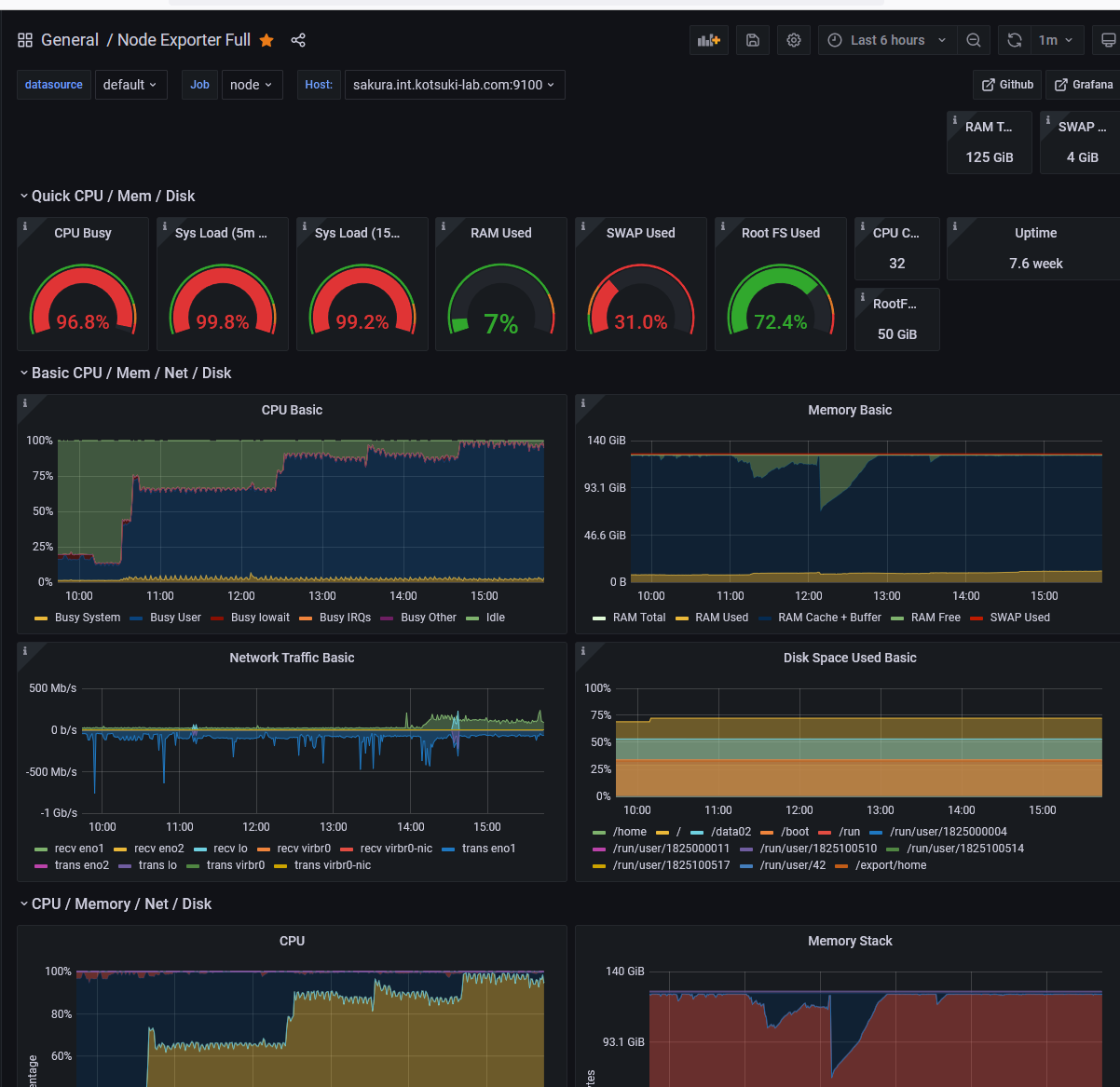
ノードの監視
Ansibleによる自動構成
自動構成ツールとしてAnsibleを使っています。Playbookはgitlabで管理しています。